
今回はお仕事の話です。
まんぼう中にログサーバにて障害が発生し、
土日2日潰した際のケーススタディです。
今回の記事は以下の方向けです。
- 運用系システムエンジニアとして活動されている方
- システムエンジニアを志している方
- システムエンジニアの仕事内容に興味がある方

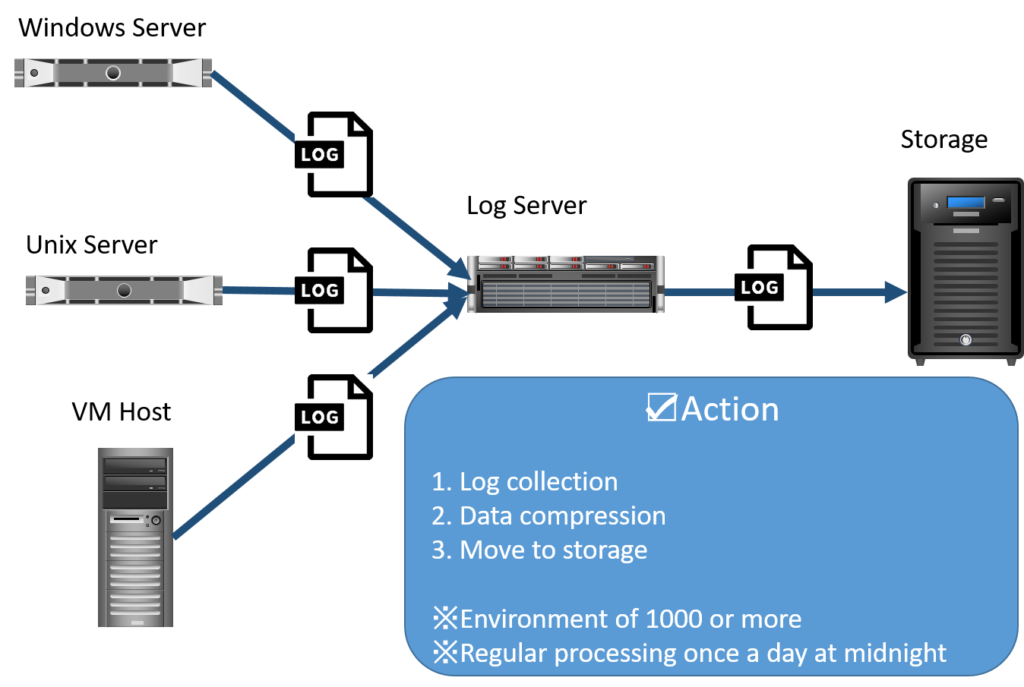
システム構成図
まず、面倒を見ているログサーバの概要図を示します。
1000台以上のノードからログを回収し、
ストレージのDiskスペースの有効活用のため
圧縮処理をした上で、ストレージへ格納しています。
序章~何故障害が発生したのか?~
土日対応発生の数日前の出来事から触れていきます。
土日対応発生までの経緯は下記3点となります。
- ログサーバからDisk閾値超過のアラート発生
- ログサーバがDiskひっ迫した原因
- 運用メンバーによる一次対処内容
- 運用メンバーによる二次対処内容
ログサーバからDisk閾値超過のアラート発生
はじまりはいつも雨。
ではなく笑
エンジニアにとっての障害対応の始まりは
いつもアラートから。
です。
当日6時ごろにDiskひっ迫のアラートが発生し、
Disk容量は増加の一途を辿り、
結局Disk使用率は100%に到達し、
後続のログ回収処理は停止してしまいました。
ログサーバがDiskひっ迫した原因
前日までは安定稼働していたログサーバですが、
突如Diskひっ迫を起こした原因は
セキュリティソフトのサイレントアップデートに伴い、
キャッシュがクリアされ、ポーリング処理によってログ容量が激増した。
ということでした。
利用しているセキュリティソフトは、
各サーバ上の資産(各ファイル)の情報を取集し、
マネージャーサーバへ転送し、
マネージャーサーバで一元管理することを
目的に利用されています。
このセキュリティソフトがサイレントアップデートされており、
マネージャーサーバ側でキャッシュがクリアされ、
ゼロから各サーバの資産情報を回収すべく、
全ファイルをポーリングする処理がなされた事で、
監査ポリシー(オブジェクトアクセス)に引っ掛かり、
セキュリティログが肥大化した。
ということが事の顛末でした。
運用メンバーによる一次対処内容
Disk使用率100%に到達している為、
身動きが取れない状況に陥っています。
そのため
Diskサイズの拡張を実施します。
ただ、注意点が1つあり、
VMware仮想基盤上にログサーバが存在するのですが、
最大で2TBまでしか拡張が出来ません。
Diskひっ迫が発生した当日中に最大値までDisk拡張し、
翌日のログ転送処理を見守ろうという事で当日の対応は終了いたしました。
運用メンバーによる二次対処内容
前日のDisk拡張も虚しく、
翌日もDisk閾値超過のアラートが発生しました。
想像を超えるログ容量の増加もあることと、
前日ログ転送処理が停止した増分も相まって、
翌日もDisk使用率100%に到達する始末です。
Disk拡張は最大値まで引き上げているので、
二次対応としてとった施策は
個別ログ転送処理の実施です。
ログ転送が出来ていないサーバに当たりをつけ、
ログ転送処理を順次実施していくという対応でした。
土日まで対応が継続したのは何故か?
土曜日もDisk使用率100%に到達したためです😢
流石に連日立て続けに障害発生しているため、
二次対処を行ったとはいえ、
翌日の土曜日の朝一の処理でDiskひっ迫が発生しないかを
見届ける方針で顧客合意を得て、週末の対応は終了しました。
土曜朝一、ログサーバの処理状況を確認したところ、
8時過ぎにはDisk使用率90%を超過し、
未だ処理件数は半分程度ということで、
このままでは確実にDisk使用率100%超過が
見込まれるため、日次処理を停止し、
どうしたものかと打開策を模索し始めるのでした。
初日(土曜日)の対応内容
検討した結果、下記段取りで連日続く
ログひっ迫対応を解消しようと作戦を立てます。
- 取得済みログのデータ圧縮・ストレージへの個別転送処理
- 取得失敗サーバリストの取得(ジョブ稼働ログから把握)
- 取得失敗サーバのログ再転送・データ圧縮・ストレージへの個別転送処理
取得済みログのデータ圧縮・ストレージへの個別転送処理
大凡2TB程のデータを圧縮しなければなりませんので、
時間効率を重視し、まずはデータ圧縮処理を開始します。
9:00過ぎに圧縮処理を仕掛けた結果、
処理が完了したのは14:00頃となりました。
その後、ストレージへの個別転送処理を実施します。
取得失敗サーバリストの取得
データ圧縮処理を実施している間、
ジョブの稼働ログ、環境調査をしていく中で
前日の二次対応に漏れがあることが判明しました。
Unix Serverについては、ログサーバからPull処理をしておらず、
Unix ServerからログサーバへPush処理をしている関係で、
ログサーバに約1TB程の未圧縮・未転送データの存在を発見します。
何故かと思い、ジョブの解析をした結果、
連日失敗しているログ転送処理と同時に
データ圧縮専用フォルダへの移動処理を行っている事がわかりました。
データ圧縮専用フォルダへの移動処理が連日実施されておらず、
Unix Serverのログが連日溜まり続けている事が
Diskひっ迫事象の一つの要因になっている事を把握します。
そのため、連日失敗しているログ転送処理を
一度成功させなければ一向に本事象は解決しない事を理解していきます。
取得失敗サーバのログ再転送・データ圧縮・ストレージへの個別転送処理
本日ログ取得失敗しているサーバリストを
ログ転送ジョブに食わせ、再度ログ転送処理を開始します。
適宜Dドライブ空き容量に目を配りつつ、
処理を見守りますが、何とかギリギリ耐え、
ログ転送処理が滞留していた全てのサーバログを
ストレージへの転送処理が完了しました。
全ての対応が完了した時刻は25:00。
事の顛末を顧客報告をし、
念のため翌日も朝一から転送処理を確認する事といたしました。
二日目(日曜日)の対応内容
8:30頃からログ転送処理を見守っていきます。
Disk使用率は50%程で9:00過ぎには
ログ転送処理が完了している事を確認。
連日続いた障害のクロージングの連絡を顧客に入れ、
一連の障害対応を終了といたしました。
障害の振り返り(反省点)
今回の障害対応を経て、
いくつか反省点がありました。
- 二次対応に漏れがあったこと
- 長らく安定稼働しているシステムであるため、障害対応手順が確立できていなかったこと
二次対応に漏れがあったこと
運用メンバーに一次対応、二次対応を任せていましたが、
土曜日の対応で私が対応した際に調査したところ、
複数日ログ転送処理が停止しているサーバが
膨大数存在していました。
土曜日の対応が長時間化したことは
平日の対応漏れの要因が大きかったと捉えています。
長らく安定稼働しているシステムであるため、障害対応手順が確立できていなかったこと
ログ転送処理が失敗しているサーバに当りを付け、
個別にログ転送処理を実施する手順は確立していたものの、
- Unix Serverのデータ圧縮・転送処理の停止
- 複数日に渡るログ未転送サーバの存在
が明らかになっており、障害対応手順の見直しが必要です。
ログサーバは10年以上既存の構成で運用していますが、
安定稼働していることと、大体一次対応内容で解消してきたため、
障害対応手順の妥当性について深堀りしてこなったシステムです。
また、ログサーバを構築した担当者は既に離任しており、
かつ設計書も存在しない状況です。
だからこそ、目を背けていた面も否定できない為、
今回の障害をきっかけに障害対応手順のブラッシュアップを
図る事で本障害がクロージングとなりました。
最後に
まんぼう中は暇なので、
ある意味、良い暇つぶしにはなりました笑


コメント